“由于未经授权的请求而被阻止 (401)”(“Blocked due to unauthorized request (401)”)状态描述了 Google Search Console 中未编入索引的页面。这意味着:
“由于未经授权的请求而被阻止 (401)”是一个值得解决的问题,因为具有此状态的页面会消耗您网站的抓取预算。此外,此错误可能会使您的一些有价值的页面无法进入 Google 索引。
服务器与浏览器和爬取程序通信的方式之一是使用状态代码。状态代码是标准化的三位数数字,其中包含有关浏览器或爬取程序请求的页面的信息。
对于需要查看登录凭据的页面,如果请求方未提供这些凭据,则会返回 401 状态代码。
如果你网页的内容受密码保护,Google 将无法抓取该网页。在大多数情况下,爬取是索引的必要步骤。
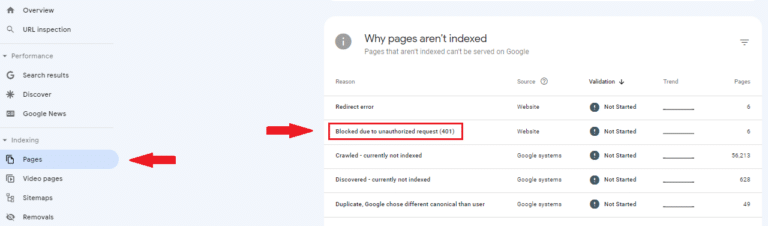
要查找受“因未经授权的请求而被阻止 (401)”状态影响的页面,请打开 Google Search Console。查看 Page Indexing 报告,该报告可从 Google Search Console 的左侧导航栏访问。
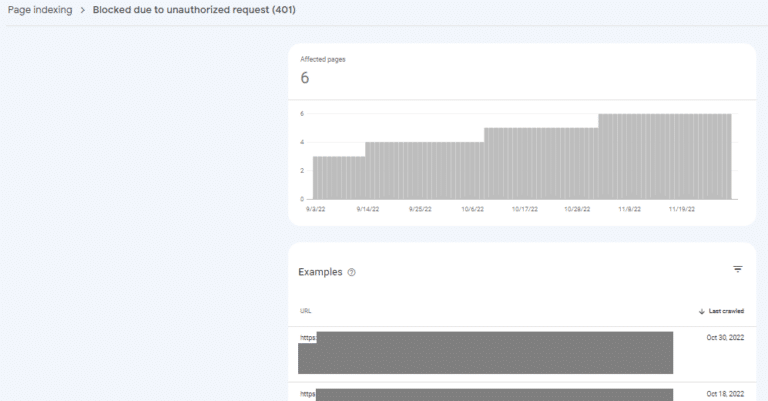
点击状态名称后,你将看到一个图表,显示受影响页面的数量如何随时间变化,以及一个 URL 列表。该列表可以导出并过滤到最感兴趣的区域。
了解向 Googlebot 返回状态代码 401 的网页后,决定哪些网页应该编入索引,哪些网页不应该编入索引。
让我向您展示如何做出这样的决定,并在这两种情况下对“Blocked due to unauthorized request (401)”页面进行故障排除。我将讨论如何让它们被索引,以及如何防止它们破坏你的爬虫。
并非你域名中的所有页面都需要编入索引。网站不太可能实现 100% 的指数覆盖率,进入指数的内容应该是一个战略决策。
此规则尤其适用于由登录墙保护的页面。 但在某些情况下,你实际上可能希望它们在 Google 上被编入索引。
我们可以将受密码保护的页面分为三种类型:
有时,应在搜索结果中显示受密码保护的页面并产生点击。
例如,你可能运行一个付费新闻网站,该网站刚刚发布了一篇有趣的文章。你希望互联网用户能够找到它并购买订阅,如果他们希望访问完整内容。在这种情况下,包含该文章的页面应该既需要用户的登录凭据,又应该被 Google 索引。
对于内容对尚未成为你网站用户的访问者无用的网页,应区别对待。这些 URL 没有理由出现在 Google 搜索和 Google 索引中。
只要你正在处理暂存环境页面,你就不希望它们是公开的并在搜索结果中排名。
这是否意味着“因未经授权的请求而被阻止 (401)”状态适用于应远离 Google 索引的暂存网页或受密码保护的网页?
很遗憾,不能,因为 Googlebot 尝试抓取它们会浪费你的抓取预算。 由于资源有限,Google 必须对抓取的频率、数量和网址进行挑剔。凌乱的未优化抓取预算意味着您的宝贵页面从搜索引擎爬虫那里得到的关注较少。
如果你将页面过滤到站点地图中提交的页面,那么区分可索引和不可索引的页面将更容易。
你包含在站点地图中的 URL 对你的网站具有战略重要性,应该包含在 Google 的索引中以产生自然流量。
确定 401 页面的归属位置后,你可以使用以下故障排除方法之一。
对于你要编入索引的 401 网页,你需要更改服务器设置,以便 Googlebot 可以访问和抓取其网址。这意味着,你的服务器必须将 Googlebot 与用户的浏览器区别对待。
通常,向 Google 显示的内容与向用户显示的内容不同是不受欢迎的,并且可能会因伪装真实内容而受到手动处罚。这就是为什么向爬虫发出信号你为什么决定使用此类解决方案很重要的原因。你可以通过将结构化数据应用于付费页面来实现这一点。Google 的指南可以指导你将哪些结构化数据添加到你的订阅页面。
你应该如何处理不属于 Google 索引的 401 页面?你可以阻止在 robots.txt 文件中抓取它们。 此文件包含指示爬网程序可以访问网站的哪些部分的指令。与独占和不可编入索引的页面或暂存页面相关的 Disallow 指令将阻止 Googlebot 在这些页面上浪费抓取预算。
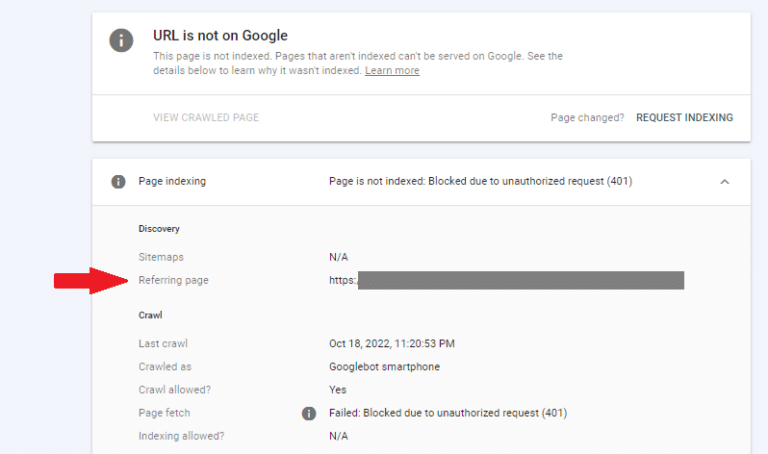
最好调查一下 Googlebot 是如何发现你不希望被编入索引的 401 网页的。为此,请使用 URL 检查工具,你可以通过单击放大镜图标从受影响的页面列表中运行该工具。
从 URL 检查工具中提供的信息中,你将了解哪些链接将爬虫引导至给定的 401 页面。
上述解决方案将有助于为对你的业务至关重要的页面编制索引,并改善你网站的抓取预算分配方式。但是,如果由于你的服务器错误而出现“由于未经授权的请求而被阻止 (401)”状态,则这些方法无法保证索引问题不会再次出现。
与任何网站一样,你的域名可以从定期的技术 SEO 审查中受益。 此类审计可让你在发生任何损害之前消除对你的可见性的威胁。 如果出现“因未经授权的请求而被阻止 (401)”问题,请使用 Nat 的综合服务器日志分析并检查你的服务器是否在与爬虫通信时遇到问题。
当 Googlebot 尝试抓取您的网页,但你的服务器请求抓取工具无法提供的登录凭据时,会出现“因未经授权的请求而被阻止 (401)”错误。
决定是否应将这些网页编入索引,并:
为确保将来问题不会再次出现,请联系Nat 并让我们的技术 SEO 专家照顾你的网站。
内容创作不易,如果觉得Nat写的东西对您有一定的帮助,请不要吝啬对Nat的赞赏,谢谢!
与Nat取得联系,我会在短时间内合理的规划关于建站,网站优化,及SEO推广方面的任何问题。